Semantic action and dataflow
Understanding the dataflow
Differentiating between faulty and correct inputs is generally only part of the job we expect from a parser. Another big part is to run routines and generate data as a side-effect. In this section, we'll talk semantic actions, dataflow, parse children and captures.
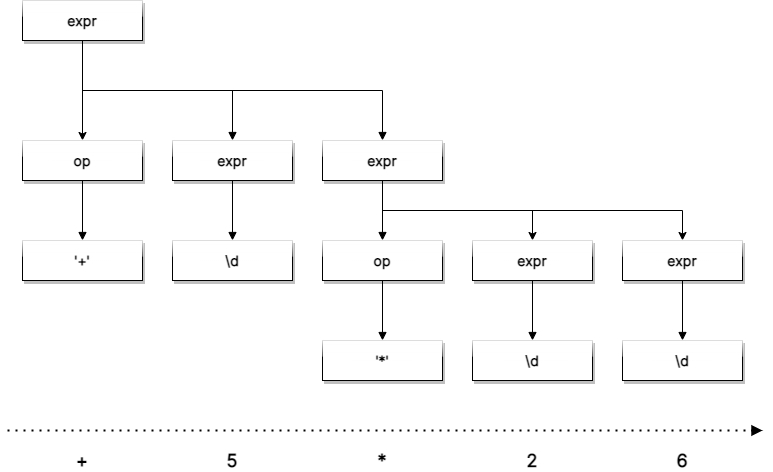
PEG parsers are top-down parsers, meaning the peg expressions are recursively invoked in a depth-first manner, guided by a left-to-right input read. This process can be represented as a tree, called concrete syntax tree. Let's illustrate that with the following grammar:
const prefix = peg`
expr: op expr expr | \d
op: '+' | '-' | '*' | '/'
`;
The input "+ 5 * 2 6" would generate the following syntax tree:
Pegase implements a mechanism by which every individual parser can emit an array of values called children.
For example, in the op rule, '+' is a parser in and of itself who will succeed if a plus character can be read from the input. It's called a literal parser. You can make any literal parser emit the substring it matched as a single child by using double quotes instead of single quotes. More generally, you can make any parser emit the substring it matched as a single child by using the @raw directive. For example, \d @raw will emit the exact digit character it matched, i.e. the input 5 would produce ["5"] as children.
children can be collected and processed in parent parsers through composition.
Some composition patterns process children automatically. This is for example the case with the sequence expression op expr expr: The children of that sequence is the concatenation of the individual children of op, expr and expr. Please refer to the table in Building parsers, column Children, for more information. We can also customize that processing behavior with the help of semantic actions as we'll discuss in a second. For now, let's rewrite the grammar to make it emit the operators and the digits it matched:
const prefix = peg`
expr: op expr expr | \d @raw
op: "+" | "-" | "*" | "/"
`;
Now children are emitted and propagated during the parsing process:
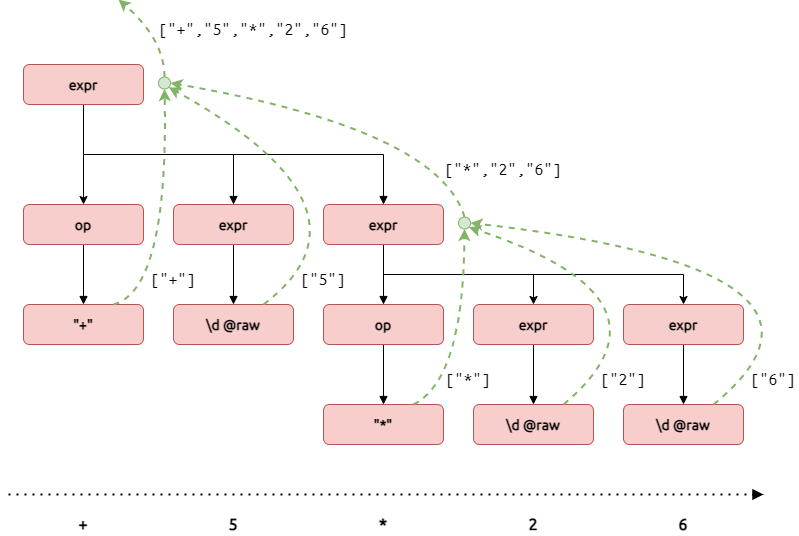
Indeed:
prefix.parse("+ 5 * 2 6").children; // ["+", "5", "*", "2", "6"]
prefix.children("+ 5 * 2 6"); // ["+", "5", "*", "2", "6"]
That can already be pretty useful, but what you usually want to do is to process these children in certain ways at strategic steps during parse time in order to incrementally build your desired output. This is where semantic actions come into play.
Semantic actions
A semantic action wraps around a Parser and calls a callback on success. If it returns undefined, children will be forwarded. Any other return value will be emitted as a single child.
Let's take our prefix grammar and say we want to make it generate the input expression in postfix notation (operators after operands). All we need to do is wrap a semantic action around op expr expr, reorder its children to postfix order, join them into a string and emit that string as a single child.
import peg, { $children } from "pegase";
const prefix = peg`
expr:
| op expr expr ${() => {
const [op, a, b] = $children();
return [a, b, op].join(" ");
}}
| \d @raw
op: "+" | "-" | "*" | "/"
`;
$children is a hook.
Hooks are global functions that provide contextual information and operations in semantic actions, like reading children, emitting warnings or failures, getting the current position, etc. Please refer to the Hooks section for a list of all available hooks.
Recursively, this process will transform the entire input from prefix to postfix:
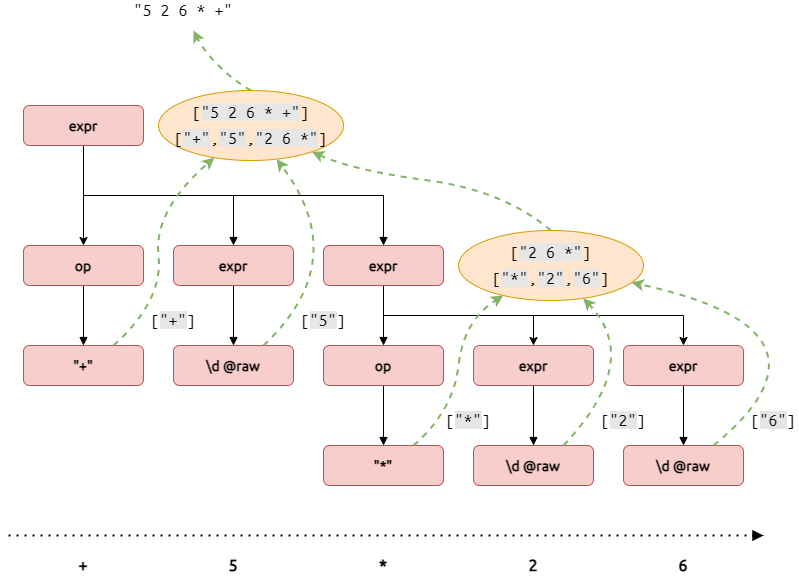
Let's test this:
prefix.children("+ 5 * 2 6"); // ["5 2 6 * +"]
When a Parser emits only a single child, it's called the value of that Parser.
prefix.parse("+ 5 * 2 6").value; // "5 2 6 * +"
prefix.value("+ 5 * 2 6"); // "5 2 6 * +"
value is undefined if there is no child, or multiple children. You can quickly convince yourself that the prefix grammar can only ever return one child. Thus, except in case of a parse failure, there is always a value to be read from prefix. A well designed peg expression should always have easily predictable children for itself and all its nested parser parts. A quick glimpse at a grammar should always give you a good general picture of the dataflow. In most cases, a good design choice is to ensure that non-terminals always emit only up to one child but that's ultimately up to you.
Great, but at the end of the day children are just unlabeled propagated values. Sometimes that's what you want (typically when you're parsing list-ish data: a list of phone numbers, a list of operators and operands, a list of arguments to a function, etc.), but very often in semantic actions, you want to be able to grab a specific parser's value by name. This is where captures will come in handy.
Captures
A capture expression <id>a binds the value (the single child) of parser a to the identifier id, which can be used in semantic actions.
Two things to keep in mind:
- If
ais a non-terminalidand you want to bind its value to its own name, you can simply write<>id(equivalent to<id>id). - Captures are passed as a semantic action's first and unique argument.
Taking this into consideration, our prefix-to-postfix converter can be rewritten in a slightly nicer way:
const prefix = peg`
expr:
| <>op <a>expr <b>expr ${({ op, a, b }) => [a, b, op].join(' ')}
| \d @raw
op: "+" | "-" | "*" | "/"
`;
As an exercise, try to rewrite the prefix grammar so that its value is the actual result of the calculation.
Custom emitted children
What if you want to emit more than one child, no child at all, or [undefined] from a semantic action ? This has to be done explicitly by calling the $emit hook which takes a custom children array as an argument:
import peg, { $emit } from "pegase";
peg`a ${() => {}}`; // forwards a's children (pass-through)
peg`a ${() => undefined}`; // forwards a's children (pass-through)
peg`a ${() => $emit([undefined])}`; // emits a single child (undefined)
peg`a ${() => 5}`; // emits a single child (5)
peg`a ${() => $emit([])}`; // emits no child
peg`a ${() => $emit([1, true, 2])}`; // emits multiple children